OpenVLA笔记
最近在看 VLA 相关模型,了解到 OpenVLA,有必要写一篇博客记录一下。本文会从数据来源、数据处理、模型构建、训练与微调、性能测试几个方面梳理其设计,并结合它在数据层与模型层的大量消融实验,总结一些可复用的工程启示。
项目总结
当时的借鉴意义(当前可能有更好的解决方案)
-
统一 的Action Space
-
EEF pose、joint space、delta control、absolute control等数据集,把不同机器人的 action 映射到统一表达,统一成 delta EEF + gripper。
-
把数据值scale 到统一数值范围,实现归一化。
-
-
把 Action 变成 LLM 可预测的 Token 序列
离散化Action (或量化)-> 转成 token -> 因果注意力掩码 LLM 预测下一个 action token
-
Projector 做跨模态对齐
projector不是简单“融合”,而是把视觉特征映射到 LLM embedding 空间。
Image → Vision Encoder → Feature ↓ Projector ↓ LLM token space ↓ Autoregressive action tokens
LLM 不直接理解 vision feature,通过 projector 对齐到 token embedding 维度,实现维度对齐、分布对齐、模态对齐。
不足与发展
不足
- OpenVLA 的输出是 自回归动作序列,逐步预测动作 token → 再还原到连续动作,这种方式在机器控制上延迟较高,难以适配高频控制需求。
- OpenVLA 用离散化 + Token 化的办法让 LLM 预测连续动作,在简单任务上可用,但:
- 离散化可能损失动作精度,
- 难捕获连续轨迹的动态变化,
- 动作预测往往更粗糙。
- 泛化/鲁棒性仍有限
- 对新场景、未见物体位置、复杂动态交互场景的泛化仍旧不够稳健;
- 在超出训练数据的数据分布时性能下降明显。
发展
截至本文写作时间2026-02-27,OpenVLA 已经过去两年,2年对于当前AI的发展来说可谓时日新月异,业界有了很多新的探索,无论时从数据的采集和自动化生成,模型架构,算法优化,数据多源,真实世界的泛化上都有了明显的进步,归根结底是用了更广泛更多的数据,从理解轨迹关系上升到空间关系,去泛化在多场景下的任务执行。
- 在数据采集上,“π0.5+ego” 是对 π0.5 框架(https://arxiv.org/abs/2512.22414)在 利用来自人类视频的 egocentric(第一视角)数据进行训练与学习;
- 在数据泛化上,上海人工智能实验室的InternVLA-M1 (https://arxiv.org/abs/2510.13778)提出 先学习空间推理(where),再学习动作控制(how)的训练模型。
- 在模型推理上,LLM的经验迁移到VLA之上,COL-VLA(https://arxiv.org/abs/2510.13778)提出先在视觉空间里规划/推演,再在动作空间里执行的策略等等。
- 处了自回归模型外,Diffusion Policy (2023, Stanford),基于扩散模型,直接在连续空间生成一次性整段轨迹。
- 更进一步的,基于世界模型的WorldVLA,将世界模型(World Model)和 VLA 统一到同一个自回归框架里。
-
至于强化学习,像是各种模型之上微调的法宝,如基于openvla之上的强化学习对齐(https://arxiv.org/abs/2505.18719)。
像之前web3.0时代一样,各种编程语言层出不穷,自以为掌握核心内存管理,操作系统知识,编译原理等即可应对上层变化,以不变应万变。在AI时代初期,同样以为掌握了深度学习的根本原理,理解参数的分布,转换与梯度,传递和数学表征等数学基础也能应对发展,随着数据越来越精细,模型优化越来越小,智能程度难度也越来越高,AI改变的是工作形式,与专业深度高低无关(FARS的论文生成足以证明)。
数据源
trajectory(轨迹):机器人从开始到结束的一段完整操作记录,通常包含图像、语言指令、动作序列。RLDS:一种常见的机器人数据组织格式,可以把不同来源的数据用统一结构表示。demo(示教):人类或脚本演示给机器人的样例,一条 demo 往往对应一个任务执行过程。
| 数据源 | 用途 | 数据量(约) | 说明 |
|---|---|---|---|
| Open X-Embodiment (OXE) 混合数据(RLDS) | 通用预训练 | 970K trajectories |
可以把它理解为“机器人领域的大型通识语料库”:覆盖多机器人、多任务、多场景。模型先在这里学会基础视觉-语言-动作对齐能力。 |
| BridgeData V2 | 任务/场景微调 | 124 GB |
更贴近真实操作场景的数据集,常用于把通用能力收敛到具体机器人平台和任务分布上。 |
| modified LIBERO RLDS | 仿真基准评测与微调 | ~10 GB |
偏标准化 benchmark 数据,适合做可复现实验和横向对比。 |
| 目标域机器人示教数据(自建) | 最后阶段域适配 | ~100 demos(经验值) |
当你把模型迁移到自己的机械臂/相机/工位时,通常还需要少量本地示教,让模型适应“你的环境细节”。 |
如果只看量级,可以把它分成三层:
- 通识层:几十万到百万级轨迹(学“常识”)。
- 领域层:10GB~100GB 级任务数据(学“本领域习惯”)。
- 本地层:几十到几百条示教(学“你的设备和现场”)。
数据处理
OpenVLA 用“每数据集一个标准化函数 + 全局统一字段协议 + 加权混采 + 统一token化训练目标”来吃掉多源异构数据。新增数据源时,主要是补 configs + transform + mixture,主训练代码基本不用改。 OpenVLA 的统一思路是:先把“异构机器人数据”映射成同一中间格式(RLDS标准字段),再走同一条训练管线。
- 核心入口函数 prismatic\vla\datasets\rlds\dataset.py make_interleaved_dataset加载数据
1.数据源注册
- 每个数据集先在配置表里定义观测/动作字段:configs.py (line 70)
OXE_DATASET_CONFIGS = { "bridge_oxe": { # Version of Bridge V2 in Open X-Embodiment mixture "image_obs_keys": {"primary": "image", "secondary": "image_1", "wrist": None}, "depth_obs_keys": {"primary": None, "secondary": None, "wrist": None}, "state_obs_keys": ["EEF_state", None, "gripper_state"], "state_encoding": StateEncoding.POS_EULER, "action_encoding": ActionEncoding.EEF_POS, } } - 每个数据集对应一个标准化函数(把原始字段改成统一键名/结构):transforms.py (line 865)
# === Registry === OXE_STANDARDIZATION_TRANSFORMS = { "bridge_oxe": bridge_oxe_dataset_transform } def bridge_oxe_dataset_transform(trajectory: Dict[str, Any]) -> Dict[str, Any]: """ Applies to version of Bridge V2 in Open X-Embodiment mixture. Note =>> In original Bridge V2 dataset, the first timestep has an all-zero action, so we remove it! """ for key in trajectory.keys(): if key == "traj_metadata": continue elif key in ["observation", "action"]: for key2 in trajectory[key]: trajectory[key][key2] = trajectory[key][key2][1:] else: trajectory[key] = trajectory[key][1:] trajectory["action"] = tf.concat( ( trajectory["action"]["world_vector"], trajectory["action"]["rotation_delta"], tf.cast(trajectory["action"]["open_gripper"][:, None], tf.float32), ), axis=-1, ) trajectory["language_instruction"] = trajectory["observation"]["natural_language_instruction"] trajectory = relabel_bridge_actions(trajectory) trajectory["observation"]["EEF_state"] = trajectory["observation"]["state"][:, :6] trajectory["observation"]["gripper_state"] = trajectory["observation"]["state"][:, -1:] return trajectory - 组装时把两者绑定到 dataset kwargs:materialize.py (line 37), materialize.py (line 86)
def make_oxe_dataset_kwargs( dataset_name: str, data_root_dir: Path, load_camera_views: Tuple[str] = ("primary",), load_depth: bool = False, load_proprio: bool = True, load_language: bool = True, action_proprio_normalization_type: NormalizationType = NormalizationType.NORMAL, ) -> Dict[str, Any]: """Generates config (kwargs) for given dataset from Open-X Embodiment.""" dataset_kwargs = deepcopy(OXE_DATASET_CONFIGS[dataset_name]) if dataset_kwargs["action_encoding"] not in [ActionEncoding.EEF_POS, ActionEncoding.EEF_R6]: raise ValueError(f"Cannot load `{dataset_name}`; only EEF_POS & EEF_R6 actions supported!") # [Contract] For EEF_POS & EEF_R6 actions, only the last action dimension (gripper) is absolute! # Normalize all action dimensions *except* the gripper if dataset_kwargs["action_encoding"] is ActionEncoding.EEF_POS: dataset_kwargs["absolute_action_mask"] = [False] * 6 + [True] dataset_kwargs["action_normalization_mask"] = [True] * 6 + [False] elif dataset_kwargs["action_encoding"] is ActionEncoding.EEF_R6: dataset_kwargs["absolute_action_mask"] = [False] * 9 + [True] dataset_kwargs["action_normalization_mask"] = [True] * 9 + [False] dataset_kwargs["action_proprio_normalization_type"] = action_proprio_normalization_type ...... # Specify Standardization Transform # 绑定函数为自定义的函数 dataset_kwargs["standardize_fn"] = OXE_STANDARDIZATION_TRANSFORMS[dataset_name] ...
2.统一动作语义与归一化
机器人动作表示(Action Encoding)方式
# Defines Action Encoding Schemes
class ActionEncoding(IntEnum):
# fmt: off
EEF_POS = 1 # EEF Delta XYZ (3) + Roll-Pitch-Yaw (3) + Gripper Open/Close (1)
JOINT_POS = 2 # Joint Delta Position (7) + Gripper Open/Close (1)
JOINT_POS_BIMANUAL = 3 # Joint Delta Position (2 x [ Joint Delta Position (6) + Gripper Open/Close (1) ])
EEF_R6 = 4 # EEF Delta XYZ (3) + R6 (6) + Gripper Open/Close (1)
# fmt: on
| 编码方式 | 表示形式 | 含义 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|
| EEF_POS | Δx, Δy, Δz + Δroll, Δpitch, Δyaw + gripper (7维) | 末端执行器在任务空间的相对位姿变化(欧拉角表示旋转) | 多机器人泛化、VLA模型、任务空间控制 | ✔ 结构无关 ✔ 易跨机器人泛化 ✔ 语义清晰 |
✘ 欧拉角存在万向节锁(gimbal lock) ✘ 旋转不连续 ✘ 需IK求解 |
| JOINT_POS | Δθ₁…Δθ₇ + gripper (8维) | 每个关节角度的相对变化 | 单机器人训练、精细控制 | ✔ 控制精确 ✔ 不需要IK ✔ 稳定性高 |
✘ 不同机器人关节数不同 ✘ 泛化能力弱 ✘ 结构强耦合 |
| JOINT_POS_BIMANUAL | 2 × (Δθ₁…Δθ₆ + gripper) (14维) | 双臂机器人每侧关节角度变化 | 双臂协作任务、Humanoid上肢 | ✔ 支持双臂协调 ✔ 直接控制 |
✘ 维度高 ✘ 泛化更难 ✘ 需严格关节顺序标准化 |
| EEF_R6 | Δx, Δy, Δz + R6(6维) + gripper (10维) | 末端执行器任务空间位姿变化,旋转用6D连续表示 | 大规模VLA、跨embodiment训练、需要高旋转稳定性的任务 | ✔ 无万向节锁 ✔ 连续光滑 ✔ 神经网络友好 ✔ 结构无关 |
✘ 维度更高 ✘ 需转换为旋转矩阵 ✘ 推理阶段仍需IK |
- 泛化能力 EEF_R6 ≥ EEF_POS » JOINT_POS > JOINT_POS_BIMANUAL
- R6 是一种旋转表示方法,不是独立的控制空间。EEF_R6 才是完整的动作编码方式。
统一动作语义
OpenVLA 在数据入口先做“动作语义对齐”,核心目标是让不同机器人平台的动作都映射到统一控制语义上。
在 prismatic/vla/datasets/rlds/oxe/materialize.py:47 可以看到,它只接受两种末端执行器动作编码:
EEF_POS:末端位姿增量(位置+姿态)+ 夹爪控制。EEF_R6:6D 旋转表示相关的末端动作 + 夹爪控制。 ```python def make_oxe_dataset_kwargs( dataset_name: str, data_root_dir: Path, load_camera_views: Tuple[str] = (“primary”,), load_depth: bool = False, load_proprio: bool = True, load_language: bool = True, action_proprio_normalization_type: NormalizationType = NormalizationType.NORMAL, ) -> Dict[str, Any]: “"”Generates config (kwargs) for given dataset from Open-X Embodiment.””” dataset_kwargs = deepcopy(OXE_DATASET_CONFIGS[dataset_name]) if dataset_kwargs[“action_encoding”] not in [ActionEncoding.EEF_POS, ActionEncoding.EEF_R6]: # 非 ActionEncoding.EEF_POS, ActionEncoding.EEF_R6 不支持 raise ValueError(f”Cannot load{dataset_name}; only EEF_POS & EEF_R6 actions supported!”)
这样做的好处是:模型看到的动作 token 空间始终一致,不会因为某个数据集动作定义特殊而破坏训练稳定性。
同一段代码还定义了两个关键 mask:
- `absolute_action_mask`:哪些动作维度是“绝对量”。这里最后一维(通常是 `gripper`)被当作绝对量。
- `action_normalization_mask`:哪些维度参与归一化。通常除了 `gripper` 外都归一化。
直观理解:
- 机械臂位姿增量是连续控制量,跨数据集尺度差异大,必须归一化。
- 夹爪开合往往是离散/二值语义(开/关),不适合按连续值做同样归一化。
### 归一化
归一化在通用 RLDS 管线里统一执行,避免“每个数据集各写一套”导致分布不一致。
入口在 `prismatic/vla/datasets/rlds/dataset.py:59` 的 `make_dataset_from_rlds`:
```python
def make_dataset_from_rlds(
name: str,
data_dir: str,
*,
train: bool,
standardize_fn: Optional[Callable[[dict], dict]] = None,
shuffle: bool = True,
image_obs_keys: Dict[str, Optional[str]] = {},
depth_obs_keys: Dict[str, Optional[str]] = {},
state_obs_keys: List[Optional[str]] = (),
language_key: Optional[str] = None,
action_proprio_normalization_type: NormalizationType = NormalizationType.NORMAL,
dataset_statistics: Optional[Union[dict, str]] = None,
absolute_action_mask: Optional[List[bool]] = None,
action_normalization_mask: Optional[List[bool]] = None,
num_parallel_reads: int = tf.data.AUTOTUNE,
num_parallel_calls: int = tf.data.AUTOTUNE,
) -> Tuple[dl.DLataset, dict]:
...
# -----------------------------------------------------------
# 从 RLDS 格式的数据构建 DLataset
#
# builder: RLDS 数据构建器
# split: 数据划分(如 "train" / "validation")
# shuffle: 是否打乱数据
# num_parallel_reads: 并行读取线程数
#
# 这里得到的是“按轨迹组织”的数据集
# -----------------------------------------------------------
dataset = dl.DLataset.from_rlds(
builder,
split=split,
shuffle=shuffle,
num_parallel_reads=num_parallel_reads
)
# -----------------------------------------------------------
# 第一步:重构数据结构(restructure)
#
# 将原始 RLDS 字段重新整理成统一格式,例如:
# {
# "observation": {...},
# "action": ...,
# "task": {...}
# }
#
# 这是轨迹级别操作,因此使用 traj_map
# -----------------------------------------------------------
dataset = dataset.traj_map(
restructure,
num_parallel_calls
)
# -----------------------------------------------------------
# 第二步:对 action 和 proprio 进行归一化
#
# normalize_action_and_proprio:
# - 使用预先计算好的 dataset_statistics
# - 按指定 normalization_type 进行标准化
#
# 常见归一化方式:
# - mean/std 标准化
# - min/max 归一化
#
# 归一化的目的:
# - 不同机器人/不同数据源数值尺度不同
# - 便于模型稳定训练
# 🔹 对整条轨迹(trajectory)中的 action 和 proprio 做数值归一化(normalization)
# 在多机器人、多数据源训练(比如 OpenVLA)中,不同数据的数值范围差异很大:有的机器人 Δx 单位是米
# 有的是厘米 有的关节角度范围 [-3.14, 3.14] 有的只在 [-0.5, 0.5] 如果不归一化,模型会非常难训练。
# 同样是轨迹级别操作
# -----------------------------------------------------------
dataset = dataset.traj_map(
partial(
normalize_action_and_proprio,
metadata=dataset_statistics,
normalization_type=action_proprio_normalization_type,
),
num_parallel_calls,
)
# -----------------------------------------------------------
# 返回:
# dataset → 处理后的数据集
# dataset_statistics → 数据统计信息(供后续反归一化或推理使用)
# -----------------------------------------------------------
return dataset, dataset_statistics
- 先加载或计算每个数据集的统计量(如均值方差、分位数边界等)。
- 再根据归一化类型和 mask 决定对哪些维度做缩放。
真正执行在 prismatic/vla/datasets/rlds/dataset.py:264:
- 通过
normalize_action_and_proprio(...)对action和proprio做标准化。
| metadata里的key | traj中的路径 |
|---|---|
| action | traj[“action”] |
| proprio | traj[‘observation’][‘proprio’] |
- OpenVLA 默认常用
BOUNDS_Q99(基于分位数边界)来降低异常值影响。 | 类型 | 公式 | 输出范围 | 适用场景 | | ———- | ——— | —— | ———— | | NORMAL | (x-μ)/σ | (-∞,∞) | 高斯分布数据 | | BOUNDS | Min-Max | [-1,1] | 控制信号 | | BOUNDS_Q99 | 分位Min-Max | [-1,1] | 多机器人混合数据(推荐) |
这一步的训练价值很直接:
- 不同数据源的动作尺度被拉到可比较范围,混合训练更稳定。
- 梯度不会被少数大幅度动作主导,优化更平滑。
- 推理时可结合保存的统计量做反归一化,恢复到真实机器人控制量。
3.统一样本结构(关键)
关键代码
def make_dataset_from_rlds(
name: str,
data_dir: str,
*,
train: bool,
standardize_fn: Optional[Callable[[dict], dict]] = None,
shuffle: bool = True,
image_obs_keys: Dict[str, Optional[str]] = {},
depth_obs_keys: Dict[str, Optional[str]] = {},
state_obs_keys: List[Optional[str]] = (),
language_key: Optional[str] = None,
action_proprio_normalization_type: NormalizationType = NormalizationType.NORMAL,
dataset_statistics: Optional[Union[dict, str]] = None,
absolute_action_mask: Optional[List[bool]] = None,
action_normalization_mask: Optional[List[bool]] = None,
num_parallel_reads: int = tf.data.AUTOTUNE,
num_parallel_calls: int = tf.data.AUTOTUNE,
) -> Tuple[dl.DLataset, dict]:
'''
Returns:
轨迹数据集,其中每个步骤包含以下字段:
- observation(观测数据):
- image_{name1, name2, ...} # RGB图像观测数据(注:花括号内为不同相机/视角的名称,如camera_left、camera_top等)
- depth_{name1, name2, ...} # 深度图像观测数据(注:与RGB图像一一对应,记录场景的深度信息)
- proprio # 本体感受观测数据的一维数组(注:如机器人关节角度、速度、力反馈等自身状态数据)
- timestep # 每一帧对应的时间步(注:标识该观测数据在轨迹序列中的时间位置)
- task(任务信息):
- language_instruction # 语言指令(注:仅当指定了`language_key`参数时才会存在该字段)
- action # 动作向量(注:该时间步执行的动作,如机器人的关节控制指令、移动指令等)
- dataset_name # 数据集名称(注:标识该条轨迹所属的数据集,用于多数据集融合场景)
'''
make_dataset_from_rlds 会把所有数据源整理成同样字段
4.统一轨迹/帧级处理(数据清洗)
统一轨迹
核心库dlimp
dlimp 是一个专门用于处理 ** 轨迹数据集(Trajectory Datasets)** 的 Python 库,常见于机器人学习、强化学习或具身智能(VLA)相关的研究中。 核心功能: DLataset 类:对 tf.data.Dataset 的轻量级封装,专为轨迹数据设计,支持从 TFRecords 或 RLDS 格式加载数据。 数据转换工具:提供 frame_map(帧级转换)和 traj_map(轨迹级转换)方法,方便对轨迹数据进行预处理。 数据集转换脚本:包含将其他格式数据集转换为 dlimp 兼容格式的工具(推荐使用 RLDS 格式)。 简单说,它是用来高效加载、处理和转换机器人 / 智能体轨迹数据的工具库。
openvla具体实现
def apply_trajectory_transforms(
dataset: dl.DLataset,
*,
train: bool,
goal_relabeling_strategy: Optional[str] = None,
goal_relabeling_kwargs: dict = {},
window_size: int = 1,
future_action_window_size: int = 0,
subsample_length: Optional[int] = None,
skip_unlabeled: bool = False,
max_action: Optional[float] = None,
max_proprio: Optional[float] = None,
task_augment_strategy: Optional[str] = None,
task_augment_kwargs: dict = {},
num_parallel_calls: int = tf.data.AUTOTUNE,
) -> dl.DLataset:
"""
在“轨迹级别”应用通用的数据变换。这类变换通常属于“重标注”类操作
(例如过滤、分块、添加目标、删除字段等)。
本函数中的变换应满足以下特性:
- 需要访问完整轨迹(不能逐帧独立处理)。
- 通常不是 CPU 密集型操作,主要是数据移动或复制。
- 不需要解码图像。
参数说明:
dataset (dl.DLataset): 待处理的数据集。
train (bool): 是否为训练集(影响是否进行子采样等操作)。
goal_relabeling_strategy (str, 可选): 目标重标注策略名称;若为 None,则不进行目标重标注。详见 `goal_relabeling.py`。"her"(Hindsight Experience Replay)、"future"(未来帧)、"final"(最后一帧)
goal_relabeling_kwargs (dict, 可选): 重标记策略(对应 goal_relabeling 模块里的函数名)传给重标记函数的参数字典
window_size (int, 可选): 将轨迹切分成片段时,每个片段的长度。10(输入过去 10 帧的状态)
future_action_window_size (int, 可选): 未来动作窗口:把当前帧之后 N 步的动作也拼接到样本中(常用于多步预测 / 扩散模型)5(拼接未来 5 步的动作)
subsample_length (int, 可选): 若指定,则在目标重标注与分块之后,将长度超过该值的轨迹子采样为该长度。将长轨迹截断 / 下采样到固定长度(避免轨迹过长爆显存)
skip_unlabeled (bool, 可选): 是否跳过没有语言标注的轨迹。
max_action (float, 可选): 若指定,则当任一轨迹中任一时间步的任一动作维度
的绝对值超过该阈值时,丢弃该轨迹。
max_proprio (float, 可选): 若指定,则当任一轨迹中任一时间步的任一
本体感觉(proprio)维度的绝对值超过该阈值时,丢弃该轨迹。
task_augment_strategy (str, 可选): 任务增强策略名称;
若为 None,则不进行任务增强。详见 `task_augmentation.py`。增强策略(动态加载 task_augmentation 模块里的函数)
task_augment_kwargs (dict, 可选): 传递给任务增强函数的额外参数。
num_parallel_calls (int, 可选): map 操作的并行调用数,默认 AUTOTUNE。并行处理的线程数 tf.data.AUTOTUNE(自动调优)
"""
# 若设置跳过无语言标注数据
if skip_unlabeled:
# 检查数据集中是否包含语言字段
if "language_instruction" not in dataset.element_spec["task"]:
raise ValueError("skip_unlabeled=True 但数据集中不存在语言标注字段。")
# 仅保留 language_instruction 非空的轨迹
dataset = dataset.filter(
lambda x: tf.math.reduce_any(x["task"]["language_instruction"] != "")
)
# 若设置最大动作阈值,则过滤超出范围的轨迹
if max_action is not None:
dataset = dataset.filter(
lambda x: tf.math.reduce_all(
tf.math.abs(x["action"]) <= max_action
)
)
# 若设置最大 proprio 阈值,则过滤超出范围的轨迹
if max_proprio is not None and "proprio" in dataset.element_spec["observation"]:
dataset = dataset.filter(
lambda x: tf.math.reduce_all(
tf.math.abs(x["observation"]["proprio"]) <= max_proprio
)
)
# 标记 observation 和 task 字典中哪些条目是 padding
dataset = dataset.traj_map(
traj_transforms.add_pad_mask_dict,
num_parallel_calls
)
# 更新 "task" 字典(进行目标重标注)
if goal_relabeling_strategy is not None:
# traj_map 是 dlimp 中针对整段轨迹的批量处理方法,需传入接收 / 返回轨迹字典的自定义函数
dataset = dataset.traj_map(
partial(
getattr(goal_relabeling, goal_relabeling_strategy),
**goal_relabeling_kwargs
),
num_parallel_calls,
)
# 任务增强必须在分块之前执行(防止修改 goal timestep 后出错)
if train and task_augment_strategy is not None:
# 执行任务增强(例如删除某些键)
dataset = dataset.traj_map(
partial(
getattr(task_augmentation, task_augment_strategy),
**task_augment_kwargs,
),
num_parallel_calls,
)
# 对 observation 和 action 进行分块:
# - observation 在第 1 维新增一个长度为 window_size 的维度
# - action 在第 1 维新增一个长度为 window_size + future_action_window_size 的维度
dataset = dataset.traj_map(
partial(
traj_transforms.chunk_act_obs,
window_size=window_size,
future_action_window_size=future_action_window_size,
),
num_parallel_calls,
)
# 若为训练模式并指定子采样长度,则进行轨迹子采样
if train and subsample_length is not None:
dataset = dataset.traj_map(
partial(
traj_transforms.subsample,
subsample_length=subsample_length
),
num_parallel_calls,
)
return dataset
4.1. 功能定位:apply_trajectory_transforms 是针对轨迹级别的数据集转换函数,主要完成过滤、重标记、分块、子采样等操作,仅处理完整轨迹数据,不涉及图像解码,计算开销低。
4.2. 核心操作流程:
- 先过滤:剔除无语言标签(
skip_unlabeled)、动作/本体感知数据超限(max_action/max_proprio)的轨迹; - 再标记:为观测/任务字典添加填充掩码;
- 后重标记/增强:按策略更新目标标签(
goal_relabeling),训练模式下执行任务增强(task_augmentation); - 最后分块/子采样:将轨迹切分为指定窗口大小的片段,训练模式下对超长轨迹进行子采样至指定长度。
4.3. 关键参数控制:
- 训练/测试模式(
train)影响任务增强和子采样是否执行; - 并行调用数(
num_parallel_calls)控制所有映射操作的并行度,默认自动适配; - 窗口参数(
window_size/future_action_window_size)决定轨迹分块的长度维度。
4.4
- 函数仅处理完整轨迹,操作以过滤、重标记、分块为主,不涉及逐帧处理和图像解码;
- 执行顺序有严格要求:任务增强需在分块前、目标重标记后完成;
- 核心过滤逻辑针对无标签数据、超限动作/本体感知数据,核心转换逻辑针对目标标签、任务增强、轨迹分块和子采样。
帧级别处理
与处理轨迹类似.注意应该先处理帧数据后进行轨迹数据处理
def apply_frame_transforms(
dataset: dl.DLataset,
*,
train: bool,
image_augment_kwargs: Union[Dict, Dict[str, Dict]] = {},
resize_size: Union[Tuple[int, int], Dict[str, Tuple[int, int]]] = {},
depth_resize_size: Union[Tuple[int, int], Dict[str, Tuple[int, int]]] = {},
num_parallel_calls: int = tf.data.AUTOTUNE,
) -> dl.DLataset:
"""
在“帧级别(frame level)”对数据进行通用变换。
这类变换通常计算量更大,例如图像解码、图像缩放、数据增强等。
参数说明:
train (bool): 是否为训练模式(影响是否执行图像增强)。
dataset (dl.DLataset): 待处理的数据集。
image_augment_kwargs (dict | Mapping[str, dict]):
传递给图像增强函数的参数。详见 `dlimp.transforms.augment_image`。
- 如果是一个普通 dict,则应用于所有图像。
- 如果是 dict[str, dict],例如 {"wrist": {...}},
则会作用于 "image_wrist"(名称由 `make_dataset_from_rlds` 中的 image_obs_keys 决定)。
- 若某些 key 不存在,则跳过对应增强。
- 若传入空 dict,则跳过所有图像增强。
resize_size (Tuple[int, int] | Mapping[str, Tuple[int, int]]):
图像 resize 的目标尺寸。
- 若为单个 (H, W),则应用于所有图像。
- 若为 dict[str, (H, W)],则针对 "image_{k}" 分别 resize。
- 若为空 dict,则跳过所有 resize。
depth_resize_size (Tuple[int, int] | Mapping[str, Tuple[int, int]]):
与 resize_size 相同,但用于深度图像。
num_parallel_calls (int):
frame_map 操作的并行调用数量,默认 AUTOTUNE。
"""
# -----------------------------------------------------------
# 工具函数:将一个作用在“非分块 observation 字典”上的函数 fn,
# 同时应用到:
# 1. 非分块的 task 字典
# 2. 分块(chunked)的 observation 字典
#
# dl.vmap(fn) 表示对 observation 中的每个时间步(或窗口)应用 fn
# -----------------------------------------------------------
def apply_obs_transform(fn: Callable[[Dict], Dict], frame: Dict) -> Dict:
# 对 task 字典直接应用变换
frame["task"] = fn(frame["task"])
# 对 observation 字典中的每个时间步分别应用变换
frame["observation"] = dl.vmap(fn)(frame["observation"])
return frame
# -----------------------------------------------------------
# 第一步:图像解码 + resize(包括 RGB 和 depth)
# 这是 CPU 开销较大的步骤
# -----------------------------------------------------------
dataset = dataset.frame_map(
partial(
apply_obs_transform,
partial(
obs_transforms.decode_and_resize,
resize_size=resize_size,
depth_resize_size=depth_resize_size,
),
),
num_parallel_calls,
)
# -----------------------------------------------------------
# 第二步:若为训练模式,进行图像数据增强
# 所有图像使用同一个随机种子(保证多视角一致增强)
# 并跳过 padding 图像
# -----------------------------------------------------------
if train:
def aug(frame: dict):
# 为当前 frame 生成一个随机种子(长度为2的 int32 向量)
seed = tf.random.uniform(
[2],
maxval=tf.dtypes.int32.max,
dtype=tf.int32
)
# 构造增强函数
aug_fn = partial(
obs_transforms.augment,
seed=seed,
augment_kwargs=image_augment_kwargs
)
# 将增强函数应用到 task 和 observation
return apply_obs_transform(aug_fn, frame)
dataset = dataset.frame_map(aug, num_parallel_calls)
return dataset
5.多数据源混合采样
多数据源+权重
- 在 OXE_NAMED_MIXTURES(数据集+权重)给不同的数据集设置不同的权重 ```python OXE_NAMED_MIXTURES: Dict[str, List[Tuple[str, float]]] = { # === Bridge V2 Dataset === “bridge”: [ # (“bridge_oxe”, 1.0), # Version of Bridge V2 in Open-X GCP Bucket (“bridge_orig”, 1.0), # Original Version of Bridge V2 from Project Website ],
### 按权重交错采样换个balance
```python
# === Core Initializer ===
def make_interleaved_dataset(
dataset_kwargs_list: List[Dict],
sample_weights: Optional[List[float]] = None,
*,
train: bool,
shuffle_buffer_size: int,
traj_transform_kwargs: Optional[Dict] = None,
frame_transform_kwargs: Optional[Dict] = None,
batch_size: Optional[int] = None,
balance_weights: bool = False,
traj_transform_threads: Optional[int] = None,
traj_read_threads: Optional[int] = None,
) -> dl.DLataset:
...
# Default to uniform sampling (if `sample_weights` is not specified)
if not sample_weights:
sample_weights = [1.0] * len(dataset_kwargs_list)
...
# Balance and Normalize Weights
if balance_weights:
sample_weights = np.array(sample_weights) * np.array(dataset_sizes)
sample_weights = np.array(sample_weights) / np.sum(sample_weights)
...
- 这样混合采样训练的好处:
- 防止小数据集被大数据集淹没。 纯拼接会让大数据集主导梯度;加权交错能保证小而关键的数据源持续被看到。
- 控制“先验偏好”与“数据规模”。 你可以先用 mixture 给任务优先级,再用 balance_weights 考虑规模,得到更合理的采样分布。
- 训练更稳、泛化更好。 多分布持续交替喂给模型,能减少对单一分布过拟合,跨场景/跨机器人表现通常更稳。
- 训练吞吐更可控。
6.构建模型数据加载器
核心函数-make_interleaved_dataset 讲之前的1-5从数据源注册、权重设置、动作统一、统一轨迹/帧级处理、动作分块等按流程顺序梳理。
模型构建
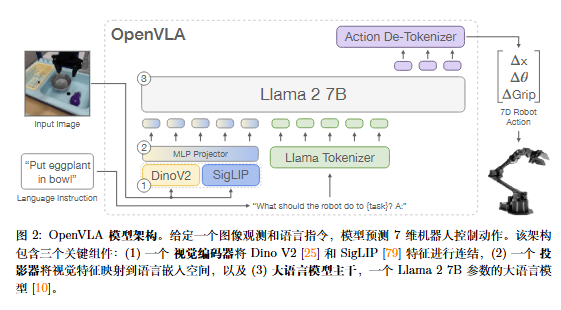
openvla在实验过程中进行了大量的实验,为我们提供了宝贵的经验。 在模型架构层面:
- 视觉模型的技术选型:只使用SigLiP的视觉编码器和采用 SigLiP+DinoV2视觉编码器
- Projector映射层连接视觉层和语言层 在模型训练层面:
- 微调冻结不同层:对全量,视觉模型参数,最后一层、projector层等冻结的性能测试 从以上需求出发,openvla不仅有良好的数据解耦兼容性,还有着良好的模型解耦兼容性,支持配置式选择不同训练阶段,支持配置式更新不同层的参数。整个框架都值得我们在AI训练业务中去学习。 在模型实验层面:
- 量化模型对性能的影响:在8bit和16bit对性能的影响
1.模型构建总览(Prismatic)
Prismatic 可以理解成 OpenVLA 的“可插拔多模态骨架”。它把系统拆成三个稳定模块:
vision_backbone:把图像变成 patch 特征;projector:把视觉特征映射到 LLM 的 embedding 空间;llm_backbone:做序列建模并输出动作 token。
这种拆分的核心价值是“架构解耦”:
- 视觉编码器可替换(SigLIP、DINOv2、双塔融合)。业内闭源的优秀模型。
- LLM 主干可替换(不同家族与规模)。业内闭源的模型。
- 中间对齐层(projector)可单独调参、单独训练。openvla项目的独有核心设计。
关键实现入口:
- 模型物化:
prismatic/models/materialize.py - 模型主干定义:
prismatic/models/vlms/prismatic.py - HuggingFace 兼容实现:
prismatic/extern/hf/modeling_prismatic.py
2.模块接口与数据流
从训练视角看,数据流是一个标准的“视觉 token 注入 LLM”路径:
-
数据侧输出统一 batch:
pixel_values / input_ids / labels
代码位置:prismatic/util/data_utils.py:198
核心函数:PaddedCollatorForActionPrediction.__call__
核心作用:把样本列表统一 pad 成模型可直接消费的 batch,并生成attention_mask与对齐后的labels。 -
视觉前向:
pixel_values -> patch_features
代码位置:prismatic/models/vlms/prismatic.py:539、prismatic/extern/hf/modeling_prismatic.py:386
核心函数:vision_backbone(...)
核心作用:把图像张量编码成 patch 级视觉特征,为后续跨模态对齐提供输入。 -
projector 对齐:
patch_features -> projected_patch_embeddings
代码位置:prismatic/models/vlms/prismatic.py:552、prismatic/extern/hf/modeling_prismatic.py:389
核心函数:projector(...)
核心作用:把视觉特征映射到 LLM embedding 空间,保证视觉 token 能与文本 token 在同一序列里建模。 -
文本 embedding 与视觉 embedding 融合:
[BOS] + visual_tokens + text_tokens
代码位置:prismatic/models/vlms/prismatic.py:563、prismatic/models/vlms/prismatic.py:566、prismatic/extern/hf/modeling_prismatic.py:403
核心函数:llm_backbone.embed_input_ids(...)+torch.cat(...)
核心作用:先得到文本 embedding,再按固定模板插入视觉 token,构建最终多模态序列。 -
送入 LLM 计算 logits/loss。
代码位置:prismatic/models/vlms/prismatic.py:647、prismatic/extern/hf/modeling_prismatic.py:429
核心函数:llm_backbone(...)/language_model(...)
核心作用:对融合序列做自回归建模,输出 logits,并在训练时基于labels计算 loss。
这条路径的工程意义是:上游换数据、下游换训练策略,模块接口基本不动。
3.视觉编码器设计(SigLIP vs SigLIP + DINOv2)
在 OpenVLA 体系里,视觉侧通常有两条路线:
- 单塔:SigLIP(更轻、训练/部署链路简单)。
- 双塔融合:SigLIP + DINOv2(语义 + 几何纹理互补,通常泛化更强)。
配置侧入口:
- 视觉 backbone 注册与选择:
prismatic/models/materialize.py:95 - HF 配置中 fused 开关:
prismatic/extern/hf/configuration_prismatic.py:119 - 双塔实现:
prismatic/models/backbones/vision/dinosiglip_vit.py
实践建议:
- 数据规模小、追求迭代速度:优先单塔 SigLIP。
- 多场景、多机器人泛化优先:优先融合视觉 backbone。
- 显存预算紧:先做单塔 + 更强数据增强,再考虑双塔。
4.LLM主干与多模态注入位置
LLM 侧承担“时序决策与动作 token 自回归”职责。OpenVLA 的关键不是改造 LLM 架构本身,而是控制注入位置与标签对齐。
注入策略:
- 先拿文本
input_ids的 embedding; - 在序列前部保留首 token(通常 BOS);
- 视觉 patch token 插到首 token 后,再接剩余文本 token。
对应实现:
embed_input_ids(...):prismatic/models/backbones/llm/base_llm.py:263- 拼接逻辑:
prismatic/models/vlms/prismatic.py:563,prismatic/models/vlms/prismatic.py:566 - HF 实现同构:
prismatic/extern/hf/modeling_prismatic.py:403
这样设计的好处是:
- 与训练模板严格对齐,避免 token 语义错位。
- 对原生 LLM 改动小,便于迁移不同 LLM 主干。
5.Projector设计与作用
Projector 是视觉空间和语言空间之间的“翻译层”,作用不是简单降维,而是做跨模态语义对齐。 Projector也做了配置式的兼容,具体代码如下,支持三种形式
class PrismaticVLM(VLM):
"""PrismaticVLM主类 - 视觉-语言模型的通用接口
"""
def __init__(
self,
model_id: str, # 模型唯一标识符
vision_backbone: VisionBackbone, # 视觉骨干网络
llm_backbone: LLMBackbone, # 语言骨干网络
enable_mixed_precision_training: bool = True, # 是否启用混合精度训练
arch_specifier: str = "gelu-mlp", # 架构指定符(投影器类型)
**kwargs,
) -> None:
super().__init__(
"prismatic", # 模型族
model_id, # 模型ID
vision_backbone, # 视觉骨干
llm_backbone, # 语言骨干
enable_mixed_precision_training=enable_mixed_precision_training,
)
# 设置投影器权重初始化种子以确保一致性
# 使用视觉嵌入维度作为随机种子,保证每次运行结果一致
torch.manual_seed(vision_backbone.embed_dim)
# 根据`arch_specifier`初始化投影(适配器)
self.arch_specifier = arch_specifier
if arch_specifier == "linear":
# 线性投影器:简单的线性变换
self.projector = LinearProjector(vision_backbone.embed_dim, llm_backbone.embed_dim)
elif arch_specifier.endswith("fused-gelu-mlp"):
# 融合MLP投影器:优化版本的多层感知机
self.projector = FusedMLPProjector(vision_backbone.embed_dim, llm_backbone.embed_dim)
elif arch_specifier.endswith("gelu-mlp"):
# 标准MLP投影器:包含GELU激活的多层感知机
self.projector = MLPProjector(vision_backbone.embed_dim, llm_backbone.embed_dim)
else:
# 不支持的架构类型
raise ValueError(f"PrismaticVLM with `{arch_specifier = }` is not supported!")
...
class LinearProjector(nn.Module):
def __init__(self, vision_dim: int, llm_dim: int) -> None:
super().__init__()
self.projector = nn.Linear(vision_dim, llm_dim, bias=True)
def forward(self, img_patches: torch.Tensor) -> torch.Tensor:
return self.projector(img_patches)
class MLPProjector(nn.Module):
def __init__(self, vision_dim: int, llm_dim: int, mlp_type: str = "gelu-mlp") -> None:
super().__init__()
if mlp_type == "gelu-mlp":
self.projector = nn.Sequential(
nn.Linear(vision_dim, llm_dim, bias=True),
nn.GELU(),
nn.Linear(llm_dim, llm_dim, bias=True),
)
else:
raise ValueError(f"Projector with `{mlp_type = }` is not supported!")
def forward(self, img_patches: torch.Tensor) -> torch.Tensor:
return self.projector(img_patches)
class FusedMLPProjector(nn.Module):
def __init__(self, fused_vision_dim: int, llm_dim: int, mlp_type: str = "fused-gelu-mlp") -> None:
super().__init__()
self.initial_projection_dim = fused_vision_dim * 4
if mlp_type == "fused-gelu-mlp":
self.projector = nn.Sequential(
nn.Linear(fused_vision_dim, self.initial_projection_dim, bias=True),
nn.GELU(),
nn.Linear(self.initial_projection_dim, llm_dim, bias=True),
nn.GELU(),
nn.Linear(llm_dim, llm_dim, bias=True),
)
else:
raise ValueError(f"Fused Projector with `{mlp_type = }` is not supported!")
def forward(self, fused_img_patches: torch.Tensor) -> torch.Tensor:
return self.projector(fused_img_patches)
在 Prismatic 里 projector 支持不同形态(线性/MLP/融合 MLP),可按视觉 backbone 结构切换:
- 见:
prismatic/models/vlms/prismatic.py:143-149 - HF 版本:
prismatic/extern/hf/modeling_prismatic.py:148,prismatic/extern/hf/modeling_prismatic.py:261
工程经验:
- 只训 projector 能快速验证数据和 prompt 链路是否通。
- projector 收敛慢时,优先查视觉 token 质量与 label 对齐,而不是盲目加深 MLP。
- backbone 大改后,projector 通常是最先需要重训的模块。
6.Action预测头与损失设计
OpenVLA 的动作预测本质是“语言建模范式下的动作 token 生成”:
- 连续动作先通过
ActionTokenizer离散化为 token 序列; - LLM 自回归预测这些动作 token;
- 再反解码回连续动作用于执行或评估。
关键代码:
- 动作分词器:
prismatic/vla/action_tokenizer.py - 训练 batch 与 label:
prismatic/vla/datasets/datasets.py:81 - label padding/IGNORE 处理:
prismatic/util/data_utils.py:216 - 多模态 label 对齐:
prismatic/models/vlms/prismatic.py:595 - 训练指标(token acc + action L1):
vla-scripts/finetune.py:330,vla-scripts/finetune.py:339
这套设计的优点是兼容现有 LLM 训练范式,缺点是离散化精度受 token 粒度约束,需要靠 tokenizer 设计和数据覆盖来补足。
7.训练配置与冻结策略(全量/视觉/末层/Projector)
OpenVLA 把冻结策略做成“配置可切换”,不是写死在单一脚本里。
@draccus.wrap()
def train(cfg: TrainConfig) -> None:
overwatch.info("OpenVLA Training :: Warming Up")
# Note => Under `torchrun` initializing `overwatch` will automatically set up `torch.distributed`
torch.cuda.set_device(device_id := overwatch.local_rank())
torch.cuda.empty_cache()
...
# Determine training "stage" based on frozen vs unfrozen parameters --> supports different fine-tuning schemes!
if not cfg.vla.freeze_vision_backbone and not cfg.vla.freeze_llm_backbone:
stage = "vla-full-train" # Full fine-tuning
elif cfg.vla.freeze_vision_backbone and not cfg.vla.freeze_llm_backbone:
stage = "vla-train" # Frozen vision encoder
elif not cfg.vla.freeze_vision_backbone and cfg.vla.freeze_llm_backbone:
assert cfg.vla.unfreeze_last_llm_layer, "You should unfreeze at least the last layer of your LLM!"
stage = "vla-sandwich-train" # Fine-tuning vision encoder, projector, and LLM last layer
elif cfg.vla.freeze_vision_backbone and cfg.vla.freeze_llm_backbone:
assert cfg.vla.unfreeze_last_llm_layer, "Need to unfreeze at least last LLM layer to train!"
stage = "vla-last-layer-train" # Fine-tuning LLM last layer only
else:
raise ValueError(
"Weight freezing configuration not supported. VLA config has the following parameters: "
f"freeze_vision_backbone: {cfg.vla.freeze_vision_backbone}"
f"freeze_llm_backbone: {cfg.vla.freeze_llm_backbone}"
f"unfreeze_last_llm_layer: {cfg.vla.unfreeze_last_llm_layer}"
)
# [Explicit] Call to `freeze_backbones` here for clarity =>> will log exactly what is/is not frozen
overwatch.info(f"Invoking `VLM.freeze_backbones()` for `{vla_id}` => Stage: `{stage}`")
vlm.freeze_backbones(stage)
......
统一配置字段:
freeze_vision_backbonefreeze_llm_backboneunfreeze_last_llm_layer
见:prismatic/conf/vla.py:45-47
执行入口:
- 训练脚本按配置推导 stage 并调用
freeze_backbones(stage):vla-scripts/train.py:176-196 - 真正的冻结/解冻逻辑:
prismatic/models/vlms/prismatic.py:243
常见阶段(可按任务难度递进):
- 只训 projector:最稳、最省显存,适合快速对齐新数据域。
- 训 projector + LLM:提升语言到动作映射能力。
- 全量微调:性能上限最高,但成本与过拟合风险也最高。
- LLM 末层解冻:作为冻结与全量之间的折中。
8.量化训练与精度权衡(8bit vs 16bit)
你提到的 8bit/16bit,本质是在“显存/吞吐/精度”之间做工程权衡。当前仓库里显式提供的是 LoRA + 4bit 量化路径:
- 量化开关:
vla-scripts/finetune.py:160 - BitsAndBytes 配置:
vla-scripts/finetune.py:204 - 默认训练精度是
bfloat16autocast:vla-scripts/finetune.py:312
可落地的经验可以写成:
bf16/fp16(16bit)通常更稳,适合作为基线。- 8bit/4bit 主要收益是降显存、提可训练规模,但会带来一定性能回退风险。
- 量化优先配合 LoRA 使用,而不是直接全参量化训练。
仿真
这一节聚焦“可复现、低风险、可快速迭代”的仿真闭环。对 OpenVLA 来说,仿真最核心的价值是:在不上真实机械臂的情况下,先把策略行为、输入输出链路和评测指标跑通。
1.目标与边界
- 训练前:验证模型推理链路是否可用(图像 -> 动作)。
- 训练后:做标准化 benchmark 对比(不同模型、不同微调策略)。
- 部署前:先在仿真确认策略稳定,再迁移真实机器人。
代码边界上,OpenVLA 把“仿真评测”和“真实机评测”分离:
- 仿真(LIBERO):
experiments/robot/libero/run_libero_eval.py - 真实机(Bridge/WidowX):
experiments/robot/bridge/run_bridgev2_eval.py
2.任务定义与评测对象
OpenVLA 在仿真侧主要对 LIBERO task suites 做评测,常见集合包括:
libero_spatiallibero_objectlibero_goallibero_10(也常被称作长序列套件)
评测目标建议固定为两层:
- 单 task 成功率(看策略对具体操作的稳定性)。
- suite 平均成功率(看整体泛化能力)。
3.仿真环境搭建(LIBERO)
按仓库 README 的路径,最小依赖链路是:
- 安装 LIBERO 本体;
- 安装 OpenVLA 仓库依赖;
- 安装
experiments/robot/libero/libero_requirements.txt。
关键参考:
- LIBERO setup 说明:
README.md(LIBERO Setup与Launching LIBERO Evaluations) - 依赖文件:
experiments/robot/libero/libero_requirements.txt
可选数据(用于复现实验):
- README 提供了
modified_libero_rlds(约 10GB)下载入口,主要用于微调/复现实验,不是跑纯评测的硬依赖。
4.评测入口与核心参数
仿真主入口:experiments/robot/libero/run_libero_eval.py:107(eval_libero)
关键参数(同文件 GenerateConfig):
task_suite_name:libero_spatial | libero_object | libero_goal | libero_10 | libero_90num_steps_wait:仿真初始稳定步数(防止初始物体抖动影响评测)pretrained_checkpoint:使用的模型检查点local_log_dir:本地日志目录
最小运行示例(以 spatial 为例):
python experiments/robot/libero/run_libero_eval.py \
--model_family openvla \
--pretrained_checkpoint openvla/openvla-7b-finetuned-libero-spatial \
--task_suite_name libero_spatial \
--center_crop True
5.执行流程(从 reset 到结果统计)
在 eval_libero 中,单个任务大致流程是:
- 初始化 task suite 与环境:
get_libero_env(...)
见:experiments/robot/libero/libero_utils.py:38 reset后先做若干 no-op 步,等待场景稳定:get_libero_dummy_action(...)
见:experiments/robot/libero/libero_utils.py:48- 从观测中提取图像并 resize:
get_libero_image(...)
见:experiments/robot/libero/libero_utils.py:70 - 调用策略生成动作,
env.step(action)推进仿真。 - 按任务成功条件累计统计,写入本地日志(可选 W&B)。
这个流程的工程意义:
- 环境适配逻辑和策略推理逻辑分层,便于替换模型或替换环境。
- no-op/warmup 机制可显著降低“非策略因素”的评测噪声。
6.指标口径与结果解释
常见核心指标:
- Task Success Rate:单任务成功率。
- Suite Average:一个 task suite 的平均成功率。
- 全局平均:多个 suite 的总体平均。
实践中建议同时记录:
- 成功率(主指标)
- 单步推理延迟(部署相关)
- 失败轨迹示例(用于定性分析)
说明:
- README 中默认提到 LIBERO 评测会跑固定数量 trials(例如 10 tasks x 50 episodes)。
- GPU 与随机种子会带来轻微波动,比较方案时要保持评测设置一致。
7.常见问题与排障
-
初始阶段动作异常:
通常是未设置num_steps_wait或 no-op 步数不足,先检查 warmup 配置。 -
结果与论文差异大:
先核对 checkpoint、task suite、center crop 策略、episode 数是否一致。 -
评测速度慢:
优先检查渲染分辨率、日志频率、GPU 推理批次策略(仿真通常是单环境时序推进,吞吐受环境 step 限制)。 -
可复现性差:
固定随机种子、固定 GPU 型号/驱动,至少重复 3 次取均值再比较。
8.工程落地建议
- 先用
libero_spatial跑通完整评测链路,再扩展到其它 suite。 - 每次改模型结构(视觉 backbone、projector、量化策略)都先做小规模仿真回归。
- 形成固定“评测卡”:命令参数、checkpoint、指标口径、日志路径,保证团队内结果可复现。
- 仿真通过后再进真实机,避免把数据/模型问题带到硬件环节。
训练和微调流程
这一节给出 OpenVLA 从“拿到数据”到“产出可评测模型”的最小闭环,重点是把流程拆成可复现的工程步骤。
1.训练模式选择(从脚本入口开始)
OpenVLA 常见两条路径:
- LoRA/参数高效微调:
vla-scripts/finetune.py - 从头训练/全量训练(分布式):
vla-scripts/train.py
推荐实践:
- 新任务先用 LoRA 跑通,确认数据和指标链路。
- 需要上限性能再考虑全量或更高训练阶段。
2.数据与批处理物化
在微调脚本中,数据链路核心是:
RLDSBatchTransform:把 RLDS 样本转成pixel_values/input_ids/labelsRLDSDataset:混合采样并输出迭代数据PaddedCollatorForActionPrediction:做 padding 与attention_mask
关键代码位置:
vla-scripts/finetune.py:273(构建RLDSDataset)vla-scripts/finetune.py:287(构建 collator)vla-scripts/finetune.py:290(构建 DataLoader)
3.模型加载与训练策略
微调脚本里模型侧流程是:
- 加载
AutoProcessor+AutoModelForVision2Seq - 可选量化配置(4bit)与 LoRA 包装
- DDP 包装 + AdamW 优化器
关键代码位置:
- 模型加载:
vla-scripts/finetune.py:217 - LoRA 配置:
vla-scripts/finetune.py:231 - DDP 包装:
vla-scripts/finetune.py:243
全量训练时,可通过冻结配置切换训练阶段:
freeze_vision_backbonefreeze_llm_backboneunfreeze_last_llm_layer见:prismatic/conf/vla.py:45-47与vla-scripts/train.py:176
4.训练循环与监控指标
OpenVLA 在训练中至少跟踪三类指标:
loss:优化目标收敛情况action token accuracy:离散动作 token 预测准确率action L1:反解码后连续动作误差
关键代码位置:
- 前向与 loss:
vla-scripts/finetune.py:312 - token acc 计算:
vla-scripts/finetune.py:330 - L1 计算:
vla-scripts/finetune.py:339
5.checkpoint 与可部署产物
训练过程中的工程要点:
- 定期保存 checkpoint,保留可回滚版本。
- 保存
dataset_statistics,用于推理时动作反归一化。 - LoRA 训练完成后可做权重合并,得到统一部署模型。
关键代码位置:
- 保存统计量:
vla-scripts/finetune.py:284 - 训练中 checkpoint:
vla-scripts/finetune.py:384
6.执行顺序
-
小数据 + 小步数 smoke test(验证链路)。
-
固定配置跑基线(记录吞吐、显存、精度)。
-
逐项改动(视觉、冻结、量化)并做回归对比。
-
仿真通过后再进真实机评测。
训练/推理加速与优化技术
FSDP
在大模型训练中,模型参数规模巨大(数十亿参数级别),如果使用传统 DDP(Data Parallel),每张 GPU 都需要保存完整模型参数副本,显存压力极大。其中 LLM Backbone 占参数大头,因此采用 FSDP 进行分片训练,支持更大的上下文长度与更大的 batch size。 FSDP(Fully Sharded Data Parallel)通过参数、梯度、优化器状态三者完全分片(Fully Sharded)的方式,大幅降低单卡显存占用。其核心机制包括:
-
参数分片存储(Shard Parameters)
-
前向传播时 All-Gather
-
反向传播后 Reduce-Scatter
-
梯度与优化器状态同样分片
优势
- 支持更大模型训练
- 显存利用率更高
- 可扩展到多节点
FlashAttention
Transformer 的 Self-Attention 复杂度为: O(n^2)当上下文长度增加时,显存和计算开销迅速增长。
FlashAttention 的核心优化
FlashAttention 通过:
- Tile-based 分块计算
- IO-aware 设计
- 避免中间 attention matrix 全量存储
将显存占用从:O(n^2)降低为:O(n)同时大幅提升吞吐。更低显存,更快计算,支持长上下文。OpenVLA 通常处理:
多帧视觉 token、语言指令 token、历史动作 token,序列长度远大于纯文本模型,因此 FlashAttention 对训练与推理都至关重要。
PageAttention
背景问题
在推理阶段,LLM 会缓存 Key / Value(KV Cache)。 如果直接连续分配显存:
- 容易造成内存碎片
- 批处理效率低
- 动态长度支持困难
PagedAttention 的思想
PagedAttention(最初由 vLLM 提出)借鉴操作系统“分页内存管理”思想:
- KV Cache 被划分为固定大小的 page
- 通过映射表管理 page
- 支持动态扩展与复用
优势
- 提高显存利用率
- 支持大规模并发推理
- 减少碎片
- 更好支持 streaming 生成
OpenVLA 中的意义
OpenVLA 在机器人场景中常常需要:
- 连续交互
- 长时间 rollout
- 保持上下文历史
PagedAttention 能有效管理长时间交互的 KV 缓存
KV Cache 优化
在自回归生成中,KV Cache 是推理加速的关键。
优化方向包括:
1️⃣ 量化 KV Cache
- FP16 → FP8
- INT8 / INT4
可显著减少显存占用。
2️⃣ 分层缓存策略
- 近期 token 保持高精度
- 远期 token 低精度压缩
3️⃣ 共享缓存
对于多请求相同 prefix:
- 共享 prefix KV
- 降低重复计算
在 OpenVLA 的指令式任务中,这类优化可以减少冷启动延迟。
混合精度与量化(AMP / FP8 / 4-bit)
训练阶段
- AMP(Automatic Mixed Precision)
- BF16 / FP16
- Grad Scaling
优势:
- 减少显存
- 提升吞吐
推理阶段
- 4-bit / 8-bit 量化
- GPTQ / AWQ 等技术
在机器人端侧部署时,量化至关重要。
推理图编译与算子融合(Torch Compile / Triton)
现代 PyTorch 提供:
- torch.compile
- AOT Autograd
- Inductor
配合 Triton:
- 自定义高效 Kernel
- 算子融合
- 减少 kernel launch 次数
对于:
- Vision Encoder
- 多模态融合层
可显著提升推理速度。
性能测试
这一节基于 OpenVLA 公开文档与脚本,客观整理性能测试流程与结果口径。
1.OpenVLA 的两类性能测试
LIBERO 仿真基准
- 入口脚本:
experiments/robot/libero/run_libero_eval.py - 评测套件:
libero_spatial / libero_object / libero_goal / libero_10 - 核心指标:各套件成功率 + 平均成功率
BridgeData V2 真实机评测
- 入口脚本:
experiments/robot/bridge/run_bridgev2_eval.py - 运行方式:WidowX server-client(Docker + 机器人服务 + OpenVLA 客户端)
- 目标:验证策略在真实控制回路里的可执行性
2.LIBERO:评测执行方式
README 中给出的流程是:
- 针对四个 LIBERO task suite 分别做 LoRA 微调(r=32)。
- 使用四个公开 checkpoint 分别评测四个 suite。
- 每个 suite 默认评测
10 tasks x 50 episodes = 500 trials。 - 多随机种子重复后汇总(论文口径为 3 个随机种子)。
对应脚本参数(GenerateConfig):
num_trials_per_task=50seedtask_suite_namecenter_crop(使用 image aug 微调时需设为 True)
关键实现文件:experiments/robot/libero/run_libero_eval.py
3.代码层:评测配置与初始化
run_libero_eval.py 的评测入口是 eval_libero(cfg),初始化阶段主要做 6 件事:
- 参数约束校验:检查 checkpoint、量化开关互斥、center crop 条件。
- 固定随机种子:
set_seed_everywhere(cfg.seed)。 - 设置反归一化键:
cfg.unnorm_key = cfg.task_suite_name。 - 加载模型与 processor:
get_model(cfg)、get_processor(cfg)。 - 初始化日志系统:本地日志文件 + 可选 W&B。
- 初始化 benchmark:读取 task suite 和任务数量。
对应代码位置:experiments/robot/libero/run_libero_eval.py:107 附近。
4.流程层:LIBERO 评测主循环
LIBERO 评测主循环是“task 外层 + episode 内层 + timestep 最内层”三层结构:
- 外层按
task_id遍历整个 suite。 - 每个 task 下按
num_trials_per_task重复 rollout。 - 每个 rollout 在
max_steps + num_steps_wait内滚动执行。
每个 step 的关键流程:
- 前
num_steps_wait先执行 no-op,等待场景稳定。 - 调用
get_libero_image(obs, resize_size)做图像预处理。 - 构造 observation 并调用
get_action(...)推理动作。 - 对 gripper 动作做环境对齐(normalize / invert)。
env.step(action)推进环境并更新reward/done/info。- 记录成功状态、轨迹日志与可选回放视频。
对应函数链路:
get_libero_env:experiments/robot/libero/libero_utils.py:38get_libero_dummy_action:experiments/robot/libero/libero_utils.py:48get_libero_image:experiments/robot/libero/libero_utils.py:70
5.流程层:Bridge 真实机评测主循环
Bridge 评测脚本 run_bridgev2_eval.py 采用“交互式 episode 循环”:
- 启动时加载模型并连接 WidowX 环境:
get_widowx_env(cfg, model)。 - 每个 episode 前输入任务文本(
get_next_task_label)。 - episode 内按控制频率节拍执行:
- 刷新观测
refresh_obs - 图像预处理
get_preprocessed_image - 动作推理
get_action - 执行动作
env.step(action)
- 刷新观测
- episode 结束后保存回放视频,可选保存 rollout 数据。
关键控制参数:
max_episodesmax_stepscontrol_frequencycenter_crop=False(脚本内有断言约束)
对应代码位置:experiments/robot/bridge/run_bridgev2_eval.py:98 附近。
6.结果记录与指标汇总机制
OpenVLA 评测脚本在实现上采用“在线统计 + 过程日志 + 可选可视化回放”:
- 在线统计:维护
total_episodes、total_successes、task 级成功数。 - 本地日志:按 run_id 写入文本日志,记录任务、episode 与成功情况。
- 可选 W&B:通过
--use_wandb上报评测结果。 - 回放视频:保存关键轨迹用于失败 case 分析。
这一套机制使得模型评测不只输出一个最终成功率,还保留了可追踪的过程证据,便于后续定位失败模式。
消融实验-论文参考
这一节建议写成“变量 -> 观察 -> 结论 -> 适用边界”,而不是只贴结果数字。这样读者能迁移到自己的业务场景。
1.视觉编码器消融
变量:
- 单塔 SigLIP
- 融合视觉编码器(如 SigLIP + DINOv2)
观察重点:
- 是否提升跨任务泛化(尤其复杂场景)
- 是否带来更高算力成本
工程结论:
- 融合视觉通常有上限优势,但要用显存和吞吐做交换。
2.冻结策略消融
变量:
- 仅训练 projector
- 训练 projector + LLM
- 全量训练
- 冻结大部分参数,仅解冻 LLM 末层
观察重点:
- 收敛速度
- 最终精度
- 训练稳定性与复现性
工程结论:
- 推荐阶梯式策略:先 low-risk(projector-only),再逐步放开参数。
3.量化/精度策略消融
变量:
- 16bit(bf16/fp16)基线
- 低比特量化(仓库中常见 LoRA + 4bit)
观察重点:
- 精度回退幅度(token acc / action L1 / success rate)
- 显存收益和吞吐收益
工程结论:
- 量化优先解决“能不能训”的资源问题,再评估“值不值得上”的精度代价。
4.数据相关消融
变量:
- 不同数据 mix 权重
- 是否启用数据增强
- 不同归一化策略(如 BOUNDS_Q99)
观察重点:
- 跨域泛化能力
- 对异常值和噪声的鲁棒性
工程结论:
- 多源混采 + 合理归一化通常比单源堆量更稳。