从零开始基于Netfilter编写一个Linux防火墙
译者序
本文翻译自国人一篇blog,详实的介绍了从如何编写一个内核模块到利用netfilter实现一个简单的mini firewalld,本文知识递进,条理清晰,对入门内核网络相关编码非常有帮助。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
摘要
防火墙是一种重要的工具,可以配置用于保护您的服务器和基础设施。防火墙的主要功能包括数据过滤、流量重定向和保护免受网络攻击。有硬件型防火墙和软件型防火墙两种。在这里,我不会过多地讨论背景,因为您可以在许多在线文档中找到相关信息。
你有没有想过从零开始实现一个简单的迷你防火墙?听起来很疯狂吗?但借助Linux的强大功能,你是可以做到的。在阅读了这一系列的文章之后,你会发现实际上这并不是太复杂。
你或许曾在Linux上使用过各种防火墙,比如iptables、nftables、UFW等。所有这些防火墙工具都是用户空间实用程序,它们都依赖于Netfilter。Netfilter是Linux内核的一个子系统,允许实现各种与网络相关的操作。Netfilter允许你使用Linux内核模块开发自己的防火墙。如果你对诸如Linux内核模块和Netfilter之类的技术不太了解,不用担心。在这篇文章中,让我们从零开始基于Netfilter编写一个Linux防火墙。你可以学到以下有趣的内容:
- Linux内核模块开发。
- Linux内核网络编程。
- Netfilter模块开发。
这篇文章会比较长,分为五个部分:
- Netfilter和内核模块背景:介绍Netfilter和内核模块的理论知识。
- 创建第一个内核模块:学习如何编写一个简单的内核模块。
- Netfilter架构和API:回顾Netfilter钩子架构和源代码。
- 实现迷你防火墙:编写迷你防火墙的代码。
Netfilter和内核模块背景
Netfilter基础知识
Netfilter可以被视为Linux上的第三代防火墙。在Linux内核2.4引入Netfilter之前,存在两代较旧的Linux防火墙,如下所述:
- 第一代是将早期版本的BSD UNIX的ipfw移植到Linux 1.1。
- 第二代是在Linux内核2.2系列中开发的ipchains。
正如我们上面提到的,Netfilter旨在为Linux内核中的各种网络操作提供基础架构。因此,防火墙只是Netfilter提供的多个功能之一,如下所示:
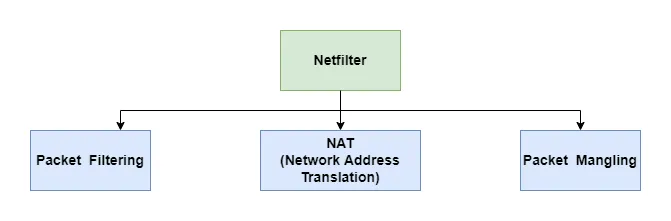
- 数据包过滤(Packet filtering):负责根据规则对数据包进行过滤。这也是本文的主题。
- 网络地址转换(NAT,Network Address Translation):负责转换网络数据包的IP地址。NAT是一个重要的协议,已经成为在IPv4地址耗尽的情况下保护全局地址空间的流行和必要工具。如果你不了解NAT协议,可以参考其他文档。我将在将来的其他文章中对其进行详细讨论。
- 数据包篡改(Packet mangling):负责修改数据包内容(实际上,NAT是数据包篡改的一种,它修改源或目标IP地址)。例如,可以修改TCP SYN数据包的最大段大小(MSS)值,以便允许在网络上传输大尺寸的数据包。
注意:本文将重点介绍如何基于Netfilter构建一个简单的数据包过滤防火墙。因此,NAT和数据包篡改部分不在本文的范围内。
数据包过滤只能在Linux内核内部进行(Netfilter的代码也在内核中),如果我们想要编写一个迷你防火墙,它必须在内核空间中运行。对吗?这是否意味着我们需要将我们的代码添加到内核中并重新编译内核?想象一下,每次想要添加新的数据包过滤规则时都必须重新编译内核,这是一个糟糕的主意。好消息是,Netfilter允许你使用Linux内核模块来添加扩展功能。
Linux内核模块基础知识
虽然Linux是一个内核单体(monolithic)架构,但它可以通过内核模块进行扩展。模块可以在需要时插入内核并进行移除。Linux在保持内核独立性的同时,允许你通过模块在运行时添加特定功能。这种方式使得Linux在稳定性和可用性之间保持平衡。
在这里,我想解释一个关于内核模块的混淆点:驱动程序与模块之间的区别:
- 驱动程序是运行在内核中的一段代码,用于与某些硬件设备进行通信。它驱动硬件。通常的做法是尽可能将驱动程序构建为内核模块,而不是静态链接到内核,因为这样更灵活。
- 内核模块未必就是设备驱动程序。
在接下来的部分中,我们将动手开始实现我们的迷你防火墙。我们将逐步走过整个过程。第一步,我们将使用一个简单的”Hello World”演示来编写我们的第一个Linux内核模块。然后我们将学习如何构建模块(这与在用户空间编译应用程序非常不同),以及如何在内核中加载它。
创建第一个内核模块
首先,我必须承认,Linux内核模块开发是一门庞大而复杂的技术领域。关于此有许多优质的在线资源可供参考。本系列文章的重点在于基于Netfilter开发迷你防火墙,因此无法涵盖内核模块本身的所有方面。在未来的文章中,我将更深入地探讨有关内核模块的知识。
编写模块
你可以通过一个单独的C源代码文件hello.c来编写”Hello World”内核模块,代码如下所示:
#include <linux/init.h> /* Needed for the macros */
#include <linux/kernel.h>
#include <linux/module.h> /* Needed by all modules */
static int __init hello_init(void)
{
printk(KERN_INFO "Hello, world\n");
return 0;
}
static void __exit hello_exit(void)
{
printk(KERN_INFO "Goodbye, world\n");
}
module_init(hello_init);
module_exit(hello_exit);
MODULE_LICENSE("GPL");
之所以可以如此轻松简单地编写内核模块,是因为Linux内核为你完成了魔术。要记住Linux(Unix)的设计哲学:以简单为设计原则,在必要时才增加复杂性。
让我们来看一下以下几个值得注意的技术要点:
首先,内核模块必须至少有两个函数:一个“启动”函数,在模块被加载到内核时调用,以及一个“结束”函数,它在模块从内核中移除之前调用。在2.3.13版本之前,这两个函数的名称被硬编码为init_module()和cleanup_module()。但在新版本中,你可以使用module_init和module_exit宏为模块的启动和结束函数使用任何你喜欢的名称。这些宏定义在include/linux/module.h和include/linux/init.h中。你可以在那里找到详细的信息。
通常,module_init要么为内核注册一个处理程序(例如,本文中开发的迷你防火墙),要么用自己的代码替换内核函数之一(通常是做某些事情,然后调用原始函数)。module_exit函数应该撤销module_init所做的任何操作,以便能够安全地卸载模块。
其次,printk函数与printf提供类似的行为,接受格式字符串作为第一个参数。printk函数原型如下所示:
int printk(const char *fmt, ...);
printk函数允许调用者指定日志级别,以表示消息发送到内核消息日志的类型和重要性。例如,在上面的代码中,通过在格式字符串前加上KERN_INFO来指定日志级别。在C编程中,这种语法称为字符串字面量连接(string literal concatenation)。(在其他高级编程语言中,通常使用+运算符进行字符串连接)。有关printk函数和日志级别的更多信息,可以在include/linux/kern_levels.h和include/linux/printk.h中找到。
注意:Linux内核模块开发的头文件路径与你通常用于应用程序开发的路径不同。不要试图在/usr/include/linux目录下找到头文件,而应使用以下路径/lib/modules/uname -r/build/include/linux(uname -r命令返回你的内核版本)。
接下来,让我们来构建这个”Hello World”内核模块。
build模块
构建内核模块的方式与构建用户空间应用程序的方式略有不同。构建内核镜像及其模块的高效解决方案是内核构建系统(Kbuild)。
Kbuild是一个复杂的主题,我在这里不会详细解释。简而言之,Kbuild允许你创建高度定制的内核二进制镜像和模块。从技术上讲,每个子目录都包含一个Makefile,仅编译该目录中的源代码文件。顶层的Makefile递归地执行每个子目录的Makefile以生成二进制对象。你可以通过定义配置文件来控制包含哪些子目录。具体细节可以参考其他文档。
以下是”Hello World”模块的Makefile示例:
obj-m += hello.o
PWD := $(CURDIR)
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
make -C dir 命令在读取 Makefile 或执行其他操作之前切换到目录 dir。位于 /lib/modules/$(shell uname -r)/build 下的顶层 Makefile 将被使用。你可以看到命令 make M=dir modules 用于构建指定目录中的所有模块。
在模块级别的 Makefile 中,obj-m 语法告诉 kbuild 系统从 module_name.c 构建 module_name.o,并在链接之后生成内核模块 module_name.ko。在我们的案例中,模块名为 hello。
构建过程如下所示:
chrisbao:~$ sudo make
make -C /lib/modules/4.15.0-176-generic/build M=/home/DIR/jbao6/develop/kernel/hello-1 modules
make[1]: Entering directory '/usr/src/linux-headers-4.15.0-176-generic'
CC [M] /home/DIR/jbao6/develop/kernel/hello-1/hello.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/DIR/jbao6/develop/kernel/hello-1/hello.mod.o
LD [M] /home/DIR/jbao6/develop/kernel/hello-1/hello.ko
make[1]: Leaving directory '/usr/src/linux-headers-4.15.0-176-generic'
构建完成后,你可以在相同的目录中得到几个新文件:
chrisbao:~$ ls
hello.c hello.ko hello.mod.c hello.mod.o hello.o Makefile modules.order Module.symvers
以 .ko 结尾的文件就是内核模块。你现在可以忽略其他文件,我稍后会写另一篇文章,深入讨论内核模块系统。
Load模块
通过使用 file 命令,你可以注意到内核模块是一个 ELF(可执行与可链接格式)格式的文件。ELF 文件通常是编译器或链接器的输出,是一种二进制格式。
chrisba:~$ file hello.ko
hello.ko: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), BuildID[sha1]=f0da99c757751e7e9f9c4e55f527fb034a0a4253, not stripped
接下来,让我们尝试动态安装和卸载模块。你需要了解以下三个命令:
lsmod:显示当前加载的内核模块列表。insmod:通过运行sudo insmod module_name.ko将模块插入到Linux内核中。rmmod:通过运行sudo rmmod module_name从Linux内核中移除模块。
由于”Hello World”模块非常简单,你可以随意安装和移除模块。我不会在这里展示详细的命令,留给读者自行尝试。
注意:这并不意味着你可以轻易地安装和移除任何内核模块而毫无问题。如果你加载的模块存在错误,整个系统可能会崩溃。
Debug模块
接下来,让我们证明”Hello World”模块已按预期安装和卸载。我们将使用 dmesg 命令。dmesg(诊断信息)可以打印内核环形缓冲区中的消息。
首先,环形缓冲区是一种数据结构,它使用单个固定大小的缓冲区,就像它们是首尾相连的一样。内核环形缓冲区是一个记录与内核操作相关消息的环形缓冲区。正如我们之前提到的,printk 函数打印的内核日志会发送到内核环形缓冲区。
我们可以使用命令 dmesg | grep world 来查找我们的模块产生的消息,如下所示:
chrisbao:~$ dmesg | grep world
[2147137.177254] Hello, world
[3281962.445169] Goodbye, world
[3282008.037591] Hello, world
[3282054.921824] Goodbye, world
现在你可以看到,”Hello World”已经成功加载到内核中。并且同样可以动态卸载。很棒。
在对内核模块有了这种理解基础之后,让我们继续我们的旅程,编写一个Netfilter模块作为我们的迷你防火墙。
Netfilter 架构
Netfilter hooks基础
Netfilter 钩子的基础知识。
Netfilter 框架在 Linux 内核中提供了一组钩子。当网络数据包在内核的协议栈中传递时,它们也会穿过这些钩子。Netfilter 允许你编写模块并在这些钩子上注册回调函数。当钩子被触发时,回调函数将被调用。这是 Netfilter 架构背后的基本思想。理解起来并不难,对吧?
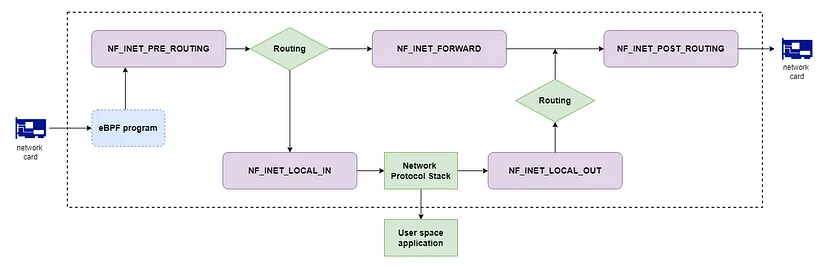
目前,Netfilter 为 IPv4 提供了以下 5 个钩子:
- NF_INET_PRE_ROUTING:在数据包被网络卡接收后立即触发。此钩子在路由决策之前触发。然后内核确定该数据包是否应发送到当前主机。基于此条件,将触发以下两个钩子。
- NF_INET_LOCAL_IN:针对目标为当前主机的网络数据包触发。
- NF_INET_FORWARD:用于应被转发的网络数据包触发。
- NF_INET_POST_ROUTING:在数据包被路由后,但发送到网络卡之前触发。
- NF_INET_LOCAL_OUT:用于当前主机上的进程生成的网络数据包触发。
你在模块中定义的钩子函数可以修改或过滤数据包,但最终必须向 Netfilter 返回一个状态码。有几种可能的代码值,但目前你只需要理解其中两个:
- NF_ACCEPT:表示钩子函数接受数据包,它可以继续在网络栈中传递。
- NF_DROP:表示数据包被丢弃,不会继续传递给网络栈的其他部分。
Netfilter 允许你在相同的钩子上使用不同优先级注册多个回调函数。如果第一个回调函数接受了数据包,那么数据包将以低优先级传递给下一个函数。如果数据包被一个回调函数丢弃,则不会遍历后续的函数(如果存在)。
正如你所看到的,Netfilter 的范围很广,我无法在这些文章中覆盖每一个细节。因此,这里开发的迷你防火墙将在钩子 NF_INET_PRE_ROUTING 上工作,这意味着它通过控制入站网络流量来实现功能。但注册钩子和处理数据包的方式可以应用于所有其他钩子。
注意:还有一个值得注意的问题是:Netfilter 和 eBPF 之间有什么区别?如果你不了解 eBPF,请参考我之前的文章。它们都是 Linux 内核中重要的网络功能。重要的是,Netfilter 和 eBPF 钩子位于内核的不同层次。如我在上面的图表中所示,eBPF 位于更低的层次。
Netfilter 钩子的内核代码
为了清楚地了解 Netfilter 框架在协议栈内是如何实现的,让我们深入挖掘一下并查看内核源代码(不用担心,只会展示几个简单的函数)。让我们以钩子 NF_INET_PRE_ROUTING 为例,因为迷你防火墙将基于它编写。
当接收到 IPv4 数据包时,它的处理程序函数 ip_rcv 将被调用,如下所示:
//In source code file /kernel-src/net/ipv4/ip_input.c
/*
* IP receive entry point
*/
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
struct net_device *orig_dev)
{
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net);
if (skb == NULL)
return NET_RX_DROP;
// run Netfilter NF_INET_PRE_ROUTING hook's callback function
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
}
在这个处理函数中,你可以看到钩子被传递给了函数 NF_HOOK。根据名称 NF_HOOK,你可以猜测它用于触发 Netfilter 钩子。对吗?让我们继续查看 NF_HOOK 的实现,如下所示:
//In source code file /kernel-src/include/linux/netfilter.h
static inline int
NF_HOOK(uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb,
struct net_device *in, struct net_device *out,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
{
int ret = nf_hook(pf, hook, net, sk, skb, in, out, okfn);
if (ret == 1)
ret = okfn(net, sk, skb); // in our case: okfn is ip_rcv_finish
return ret;
}
/**
* nf_hook - call a netfilter hook
*
* Returns 1 if the hook has allowed the packet to pass. The function
* okfn must be invoked by the caller in this case. Any other return
* value indicates the packet has been consumed by the hook.
*/
static inline int nf_hook(u_int8_t pf, unsigned int hook, struct net *net,
struct sock *sk, struct sk_buff *skb,
struct net_device *indev, struct net_device *outdev,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
{
// code omit
}
函数 NF_HOOK 包含两个步骤:
- 首先,通过调用底层函数
nf_hook运行钩子的回调函数。 - 其次,在数据包通过钩子函数并且没有被丢弃时,调用函数
okfn(作为参数传递给NF_HOOK)。 对于钩子NF_INET_LOCAL_IN,在钩子函数通过后将调用函数ip_rcv_finish。其工作是将数据包传递给协议栈中的下一个协议处理程序(如 TCP 或 UDP)继续其旅程!
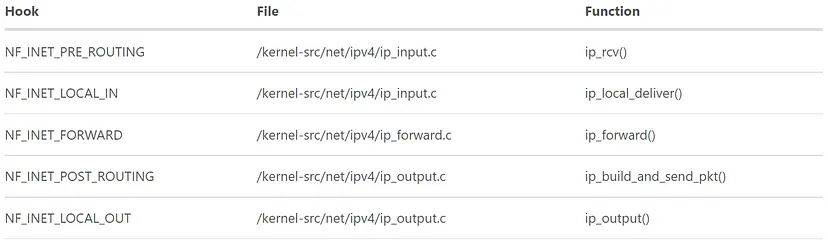
其他四个钩子都使用相同的函数 NF_HOOK 来触发回调函数。下表显示了这些钩子嵌入在内核中的位置,我留给读者们去探索。
接下来,让我们回顾一下用于创建和注册钩子函数的 Netfilter API。
定义一个 hook 函数
hook 函数的名称可以随意选择,但必须遵循以下签名:
unsigned int hook_function(
const struct nf_hook_ops *ops,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *)
)
hook 函数可以对存储在 sk_buff 结构中的数据的数据包进行修改或过滤(在我们的迷你防火墙中,我们可以忽略其他两个参数)。正如我们之前提到的,回调函数必须返回一个 Netfilter 状态代码,它是一个整数。例如,接受和丢弃状态可以定义如下:
#define NF_ACCEPT 0x0000
#define NF_DROP 0x0001
在 hook 函数中,你可以检查数据包的内容,然后决定是接受还是丢弃它。然后返回相应的状态代码,以告诉 Netfilter 框架如何处理这个数据包。
注册和注销 hook 函数
要注册一个 hook 函数,我们应该将已定义的 hook 函数与相关信息(例如,要绑定到哪个 hook、协议族和 hook 函数的优先级)封装到一个名为 struct nf_hook_ops 的结构体中,并将其传递给函数 nf_register_net_hook。
//In source code file /kernel-src/include/linux/netfilter.h
struct nf_hook_ops {
/* User fills in from here down. */
nf_hookfn *hook; // callback function
struct net_device *dev; // network device interface
void *priv;
u_int8_t pf; // protocol
unsigned int hooknum; // Netfilter hook enum
/* Hooks are ordered in ascending priority. */
int priority; // priority of callback function
};
大部分字段都很容易理解。需要强调的是 hooknum 字段,它就是上面讨论过的 Netfilter 钩子。它们被定义为枚举值,如下所示:
// In source code file /kernel-src/include/uapi/linux/netfilter.h
enum nf_inet_hooks {
NF_INET_PRE_ROUTING,
NF_INET_LOCAL_IN,
NF_INET_FORWARD,
NF_INET_LOCAL_OUT,
NF_INET_POST_ROUTING,
NF_INET_NUMHOOKS,
NF_INET_INGRESS = NF_INET_NUMHOOKS,
};
接下来,我们来看一下注册和注销 hook 函数的函数如何操作:
int nf_register_net_hook(struct net *net, struct nf_hook_ops *reg);
void nf_unregister_net_hook(struct net *net, struct nf_hook_ops *reg);
第一个参数 struct net 与网络命名空间有关,暂时我们可以忽略它并使用默认值。
接下来,让我们基于这些 API 来实现我们的迷你防火墙。可以吗?
实现mini-firewall
首先,我们需要澄清迷你防火墙的要求。我们将在迷你防火墙中实现两条网络流量控制规则,如下所示:
- 网络协议规则:丢弃 ICMP 协议的数据包。
- IP 地址规则:丢弃来自特定 IP 地址的数据包。
已经完成的代码实现在此 GitHub 仓库中。
Drop ICMP 协议包
ICMP 是现实世界中广泛使用的网络协议。流行的诊断工具如 ping 和 traceroute 使用 ICMP 协议。我们可以基于 IP 头中的协议类型过滤掉 ICMP 数据包,下面是实现这个功能的 hook 函数代码
// In mini-firewall.c
static unsigned int nf_blockicmppkt_handler(void *priv, struct sk_buff *skb, const struct nf_hook_state *state)
{
struct iphdr *iph; // IP header
struct udphdr *udph; // UDP header
if(!skb)
return NF_ACCEPT;
iph = ip_hdr(skb); // retrieve the IP headers from the packet
if(iph->protocol == IPPROTO_UDP) {
udph = udp_hdr(skb);
if(ntohs(udph->dest) == 53) {
return NF_ACCEPT; // accept UDP packet
}
}
else if (iph->protocol == IPPROTO_TCP) {
return NF_ACCEPT; // accept TCP packet
}
else if (iph->protocol == IPPROTO_ICMP) {
printk(KERN_INFO "Drop ICMP packet \n");
return NF_DROP; // drop TCP packet
}
return NF_ACCEPT;
}
上述 hook 函数中的逻辑很容易理解。首先,我们从网络数据包中提取 IP 头。然后根据头部中的协议类型字段,我们决定接受 TCP 和 UDP 数据包,但丢弃 ICMP 数据包。需要注意的唯一技术问题是函数 ip_hdr,它是内核函数,定义如下:
//In source code file /kernel-src/include/linux/ip.h
static inline struct iphdr *ip_hdr(const struct sk_buff *skb)
{
return (struct iphdr *)skb_network_header(skb);
}
// In source code file /kernel-src/include/linux/skbuff.h
static inline unsigned char *skb_network_header(const struct sk_buff *skb)
{
return skb->head + skb->network_header;
}
函数 ip_hdr 将任务委托给了函数 skb_network_header。它基于以下两个数据获取 IP 头:
head:是指向数据包的指针;network_header:是从指向数据包的指针到指向网络层协议头的指针之间的偏移量。详细信息可以参考这个文档。
接下来,我们可以将上述的 hook 函数注册如下:
// In mini-firewall.c
static struct nf_hook_ops *nf_blockicmppkt_ops = NULL;
static int __init nf_minifirewall_init(void) {
nf_blockicmppkt_ops = (struct nf_hook_ops*)kcalloc(1, sizeof(struct nf_hook_ops), GFP_KERNEL);
if (nf_blockicmppkt_ops != NULL) {
nf_blockicmppkt_ops->hook = (nf_hookfn*)nf_blockicmppkt_handler;
nf_blockicmppkt_ops->hooknum = NF_INET_PRE_ROUTING;
nf_blockicmppkt_ops->pf = NFPROTO_IPV4;
nf_blockicmppkt_ops->priority = NF_IP_PRI_FIRST; // set the priority
nf_register_net_hook(&init_net, nf_blockicmppkt_ops);
}
return 0;
}
static void __exit nf_minifirewall_exit(void) {
if(nf_blockicmppkt_ops != NULL) {
nf_unregister_net_hook(&init_net, nf_blockicmppkt_ops);
kfree(nf_blockicmppkt_ops);
}
printk(KERN_INFO "Exit");
}
module_init(nf_minifirewall_init);
module_exit(nf_minifirewall_exit);
上述逻辑是自解释的,我就不在这里花费太多时间了。
接下来,是时候演示一下我们的迷你防火墙是如何工作的了。
Demo演示
在加载迷你mini_firewall模块之前,ping 命令可以正常工作:
chrisbao@CN0005DOU18129:~$ lsmod | grep mini_firewall
chrisbao@CN0005DOU18129:~$ ping www.google.com
PING www.google.com (142.250.4.103) 56(84) bytes of data.
64 bytes from sm-in-f103.1e100.net (142.250.4.103): icmp_seq=1 ttl=104 time=71.9 ms
64 bytes from sm-in-f103.1e100.net (142.250.4.103): icmp_seq=2 ttl=104 time=71.8 ms
64 bytes from sm-in-f103.1e100.net (142.250.4.103): icmp_seq=3 ttl=104 time=71.9 ms
64 bytes from sm-in-f103.1e100.net (142.250.4.103): icmp_seq=4 ttl=104 time=71.8 ms
^C
--- www.google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3005ms
rtt min/avg/max/mdev = 71.857/71.902/71.961/0.193 ms
相反,在构建和加载迷你防火墙模块之后(基于我们之前讨论的命令):
chrisbao@CN0005DOU18129:~$ lsmod | grep mini_firewall
mini_firewall 16384 0
chrisbao@CN0005DOU18129:~$ ping www.google.com
PING www.google.com (142.250.4.105) 56(84) bytes of data.
^C
--- www.google.com ping statistics ---
6 packets transmitted, 0 received, 100% packet loss, time 5097ms
你可以看到所有的数据包都丢失了,因为它们被我们的迷你防火墙丢弃了。我们可以通过运行命令 dmesg 来验证这一点:
chrisbao@CN0005DOU18129:~$ dmesg | tail -n 5
[ 1260.184712] Drop ICMP packet
[ 1261.208637] Drop ICMP packet
[ 1262.232669] Drop ICMP packet
[ 1263.256757] Drop ICMP packet
[ 1264.280733] Drop ICMP packet
但其他协议的数据包仍然可以通过防火墙。例如,命令 wget 142.250.4.103 可以正常返回,如下所示:
chrisbao@CN0005DOU18129:~$ wget 142.250.4.103
--2022-06-25 10:12:39-- http://142.250.4.103/
Connecting to 142.250.4.103:80... connected.
HTTP request sent, awaiting response... 302 Moved Temporarily
Location: http://142.250.4.103:6080/php/urlblock.php?args=AAAAfQAAABAjFEC0HSM7xhfO~a53FMMaAAAAEILI_eaKvZQ2xBfgKEgDtwsAAABNAAAATRPNhqoqFgHJ0ggbKLKcdinR4UvnlhgAR4~YyrY4tAnroOFkE_IsHsOg9~RFPc7nEoj6YdiDgqZImAmb_xw9ZuFLvF91P2HzP5tlu1WX&url=http://142.250.4.103%2f [following]
--2022-06-25 10:12:39-- http://142.250.4.103:6080/php/urlblock.php?args=AAAAfQAAABAjFEC0HSM7xhfO~a53FMMaAAAAEILI_eaKvZQ2xBfgKEgDtwsAAABNAAAATRPNhqoqFgHJ0ggbKLKcdinR4UvnlhgAR4~YyrY4tAnroOFkE_IsHsOg9~RFPc7nEoj6YdiDgqZImAmb_xw9ZuFLvF91P2HzP5tlu1WX&url=http://142.250.4.103%2f
Connecting to 142.250.4.103:6080... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3248 (3.2K) [text/html]
Saving to: ‘index.html’
index.html 100%[===================================================================================================================>] 3.17K --.-KB/s in 0s
2022-06-25 10:12:39 (332 MB/s) - ‘index.html’ saved [3248/3248]
接下来,让我们尝试禁止来自这个 IP 地址的流量。
Drop 源地址为特定IP的数据包
正如我们之前提到的,允许在同一个 Netfilter 钩子上注册多个回调函数。因此,我们将使用不同的优先级定义第二个钩子函数。这个钩子函数的逻辑如下:我们可以从 IP 头中获取源 IP 地址,并根据它做出丢弃或接受的决定。代码如下所示:
// In mini-firewall.c
#define IPADDRESS(addr) \
((unsigned char *)&addr)[3], \
((unsigned char *)&addr)[2], \
((unsigned char *)&addr)[1], \
((unsigned char *)&addr)[0]
static char *ip_addr_rule = "142.250.4.103";
static unsigned int nf_blockipaddr_handler(void *priv, struct sk_buff *skb, const struct nf_hook_state *state)
{
if (!skb) {
return NF_ACCEPT;
} else {
char *str = (char *)kmalloc(16, GFP_KERNEL);
u32 sip;
struct sk_buff *sb = NULL;
struct iphdr *iph;
sb = skb;
iph = ip_hdr(sb);
sip = ntohl(iph->saddr); // get source ip address;
sprintf(str, "%u.%u.%u.%u", IPADDRESS(sip)); // convert to standard IP address format
if(!strcmp(str, ip_addr_rule)) {
return NF_DROP;
} else {
return NF_ACCEPT;
}
}
}
这个钩子函数使用了两个有趣的技术:
-
ntohl:是一个内核函数,用于将值从网络字节顺序转换为主机字节顺序。字节顺序与计算机科学中的字节序概念(Endianness)有关。字节序定义了计算机内存中数字数据的字的顺序或序列。大端系统将字的最高有效字节存储在最小的内存地址处。而小端系统则相反,在最小的地址处存储最低有效字节。网络协议使用大端系统。但不同的操作系统和平台使用不同的字节序。因此可能需要根据主机机器进行这种转换。 -
IPADDRESS:是一个宏,用于从一个32位整数生成标准的 IP 地址格式(四个由点分隔的8位字段)。它使用了 C 语言中数组和指针的等价性技术。我会写另一篇文章来解释这是什么以及它是如何工作的。请继续关注我的更新!
接下来,我们可以按照上面讨论的方式注册这个钩子函数。唯一值得注意的是,这个回调函数应该有不同的优先级,如下所示:
static int __init nf_minifirewall_init(void) {
<-omit code->
nf_blockipaddr_ops = (struct nf_hook_ops*)kcalloc(1, sizeof(struct nf_hook_ops), GFP_KERNEL);
if (nf_blockipaddr_ops != NULL) {
nf_blockipaddr_ops->hook = (nf_hookfn*)nf_blockipaddr_handler;
nf_blockipaddr_ops->hooknum = NF_INET_PRE_ROUTING; // register to the same hook
nf_blockipaddr_ops->pf = NFPROTO_IPV4;
nf_blockipaddr_ops->priority = NF_IP_PRI_FIRST + 1; // set a higher priority
nf_register_net_hook(&init_net, nf_blockipaddr_ops);
}
<-omit code->
}
更多的扩展空间
你可以在这里找到完整的 代码实现。但我必须说,我们的迷你防火墙只触及了 Netfilter 可以提供的表面。你可以不断扩展功能。例如,目前规则是硬编码的,为什么不使其能够动态配置规则呢?还有许多值得尝试的酷炫想法。我留给读者们去尝试。
总结
在这篇文章中,我们逐步实现了迷你防火墙,并检查了许多详细的技术。不仅仅是代码;我们还通过运行真实的演示来验证了mini_firewall的行为。